
Get started with web scraping with puppeteer.js!
Since you have found this article, I am going to assume that you know what web scraping is and want to see puppeteer in action, either before deciding if you should use this library or using this as a follow along tutorial to how to use it. Keeping that in mind, in this article, I will walk you through the code to make a scraper to download the images from a user’s public profile.
I recently came across puppeteer.js, a node library that in their own terms:
...provides a high-level API to control Chrome or Chromium over the DevTools Protocol. Puppeteer runs headless by default, but can be configured to run full (non-headless) Chrome or Chromium.It is a really powerful library and can be used for a variety of tasks, web scraping being one of them. Since I prefer using Python for most of my tasks, I would’ve used selenium and bs4 for web scraping, but I was amazed by the functionalities that this js library provides.
Expectations
The primary goal for this project was to create a program that would take the user’s ig handle and the number of posts (count) you would like to download and download them to your computer for you.
A brief word
Since I am going to focus more on the scraping part rather than the express routing and other parts, I am going to skip over the directory structure and project initialization and focus more on the code functionality.
If you want to follow along, the code can be found at my GitHub profile. I will give a brief overview of the project directory towards the end so you can skip to the end if you just wanna go through the code. So, let’s get into it!
Starting off
Before starting the project, I had the rough outline in mind as to create an express server and expose an API endpoint that would take the handle and count as parameters and return a JSON object having an array containing the image URLs.
Then, you could either save these URLs to a CSV file and write another program to download the images to the file system or create another server/script for this task (I’ll cover the reason later but one of the reason is that I found it easier to work with files in python than node’s fs).
We first import the library (puppeteer) and initialize it to create an instance of the browser and the page. We launch the browser in the headless state for testing so that we can see what is going on, but you can choose to run it in a headless state. We then create a new page and navigate to the profile page of the user. We specify the networkidle2 parameter to consider the navigation successful when there are no 2 requests for half a second.
instagram.browser = await puppeteer.launch({headless: false});
instagram.page = await instagram.browser.newPage();
await instagram.page.goto(profilePage, {waitUntil: 'networkidle2'});We will now go to a public profile on Instagram and try to find a unique way to select the posts so that we can extract the image URL. From the inspect element chrome dev tool, we can see that all images are inside the <div> tag with class KL4Bh which itself is in a <div> tag under a <a> tag.
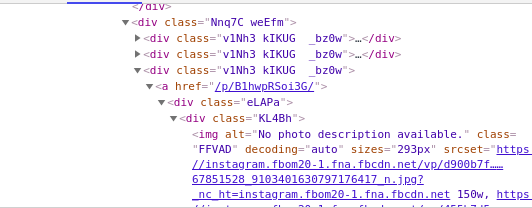
Thus we can select that element using the document.querySelectorAll(selector) method to select the elements. However, since we do not have access to the DOM, we need to make use of a puppeteer function - page.$$(selector) that does it for us. You could also make use of the page.evaluate() method which runs a piece of code in the DOM and returns the value to the program. The documentation does a fairly good job of explaining the methods available and can be found here.
After we have all the nodes, we will be able to iterate over it and do all kinds of things with it.
We select all the nodes that contain our image tags using the above-mentioned method, which returns an array of HTML nodes. Then we iterate over the entire array and extract the image URLs from them (by trial and error in the browser console), and store the images in an array of results.
let result = []
while(count < limit){
const nodes = await instagram.page.$$("a>div>div.KL4Bh");
console.log('Selected nodes: ', nodes.length);
for(let i=0;i<nodes.length;i++){
res = await instagram.page.evaluate(el => el.firstChild.src, nodes[i]);
result.push(res);
count+=1;
}
}However, there are multiple problems with this approach. First of all, we are incrementing count after pushing the URL to the results array, but we are not checking if the URL already in the array, which causes it to return us duplicate values in the array. Also, we need to figure out a way to scroll to the bottom of the page after we have selected and added the values that are currently in the scope (since Instagram uses lazy loading and there are only a specified number of images in the scope currently, and it will fetch images from the server if you have scrolled too far up or down). Thus, we need to add a check to add the values to the result only if it is not present in the array and implement the scrolling behavior. This is done as:
while(count < limit && flag){
const nodes = await instagram.page.$$("a>div>div.KL4Bh");
for(let i = 0; i < nodes.length; i++){
res = await instagram.page.evaluate(el => el.firstChild.src, nodes[i]);
if(!result.includes(res)){
result.push(res);
count+=1;
}
}
await instagram.page.evaluate(_ => {
window.scrollBy(0, window.innerHeight);
});
await instagram.page.waitFor(3000);
}So, now that we have the array of URLs we can call it a day, neh? Hold it right there sparky! There is still one small detail that we haven’t taken care of. There is still the case where the user has only say, 5 posts, but we are trying to scrape the last 100 of his posts. In this case, our code will still try to scroll down even after it reaches the end and we will waste a lot of time here. Thus, we need to figure out a way to terminate the loop if there are no updates in the result. One way to do this is to store the length of the result array in another array, then compare the last 5 elements of that array and terminate the loop if they all are some, i.e., terminate the loop if no elements are added in 5 consecutive iterations (since the results are not appended if they already exist in the result array). The final code will look something like :
result = []
count = 0
// Implement feature to stop after either getting {{ limit }} posts or if no new element is selected for say 10 iterations
len_over_time = []
let flag = true;
while(count<limit && flag){
const nodes = await instagram.page.$$("a>div>div.KL4Bh");
if(nodes.length==0){
return [];
}
for(let i=0;i<nodes.length;i++){
res = await instagram.page.evaluate(el => el.firstChild.src, nodes[i]);
// Add only if the img is not already present
if(!result.includes(res)){
result.push(res);
count+=1;
}
}
len_over_time.push(result.length);
// Check only when the length array > 5 (or always terminates in the first few iterations)
if(len_over_time.length>5){
// If all 5 elements are the same (length does not increase in 5 iterations), set will contain only 1 element
if(new Set(len_over_time.slice(-5)).size==1){
flag = false;
}
}So, this is it (for most of the part anyways). You just need to create a server(http/express) and call this function from it.
After everything is done, you need to close the browser instance with:
await browser.close();Now, for downloading the images, I created a flask server that takes the array of images as input and downloads them. To speed up the process, I made use of the multiprocessing module in python that divides the array into chunks and hands these chunks off to different processes. I tried using multithreading too but it (counter-intuitively) slowed down the code with an increasing number of threads (apparently due to the GIL implementation which slows it down since only one thread can acquire the gil at a time). I’m not going into the details for the efficiency and how the downloading was handled (mainly because it is in python and it is highly readable), but I will probably write about multithreading and multiprocessing in python soon.
Now, as promised earlier, here is the directory structure:
./
|- app.js: Entry point to the code, routes to ./server
|- instagram.js: All the actual code lives here.
|-server/
|- index.js: Routes requests to appropriate file
|- public.js: Driver code for the functions in instagram.js
|-app.py: Flask server to download imagesThe demo can be found in the README file of the repository
Edit: I have also added a dockerfile for the project so you could just use:
docker run --rm -it syn3rman/instascrape